지금까지 형태소 분석이 무엇인지, 어떤 툴을 쓰는지에 대해 알아봤다.
이번 포스팅에서는 어떻게 원하는 명사를 분리하는지에 대해 알아보겠다.
Dictionary
먼저 Dictionary는 형태소 분석 시에 참고하는 데이터셋이다.
예를 들어, CalyFactory 프로젝트에서는 사용자 데이터 분석을 위해
‘3시 홍익대에서 친구랑 약속’이라는 이벤트에서 추출을 해보자.
이를 추출하기 위해서 ‘3-시’라는 음절 간의 결합이 시간, ‘홍-익-대’라는 음절 간의 결합이 장소 정보이며 그 원형은 ‘홍익대학교’라는 정보가 필요하다.
이를 위해 ‘홍익대’는 ‘홍익대학교’라는 음절 결합에 대한 정보가 저장되어있는 부분이 Dictionary이다.
이 중에서도 System Dictionary와 User Dictionary로 나눌 수 있는데,
우리가 쓰는 Mecab의 System Dictionary는 은전한닢(Mecab-ko 프로젝트)의 프로젝트를 그대로 쓸 것이다. (설치 과정 출처 동일)
모든 작업은 리눅스 기준으로 진행한다.
1. mecab-ko 설치
다운로드 링크에서 최신 버전의 mecab-xxx-ko-x.x.x.tar.gz를 다운받아서 설치한다.
wget -c https://bitbucket.org/eunjeon/mecab-ko/downloads/최신버전-mecab.tar.gz
tar zxfv 최신버전-mecab.tar.gz
cd 최신버전-mecab
./configure
make
make check
sudo make install
2. mecab-ko-dic 설치
다운로드 링크에서 최신 버전의 mecab-xxx-ko-x.x.x.tar.gz를 다운받아서 설치한다.
wget -c https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/최신버전-mecab-ko-dic.tar.gz
tar zxfv 최신버전-mecab-ko-dic.tar.gz
cd 최신버전-mecab-ko-dic
./configure
make
make check
sudo make install
다음과 같은 과정을 거치면 기본으로 /usr/local/lib/mecab/dic/mecab-ko-dic에 설치가 된다.
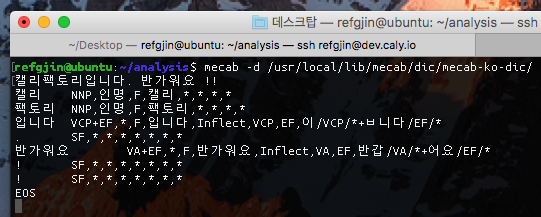
mecab -d /usr/locab/lib/mecab/dic/mecab-ko-dic
(샘플텍스트 문장 입력)
[EOS, Enter]
설치를 마친 후, 위 커맨드를 입력하면 다음과 같은결과를 볼 수 있다.
3. Konlpy 이용
다음과 같은 공식 Doc의 소스를 통해 적용된 것을 확인할 수 있다.
from konlpy.tag import Mecab
mecab = Mecab()
print(mecab.morphs(u'영등포구청역에 있는 맛집 좀 알려주세요.'))
['영등포구', '청역', '에', '있', '는', '맛집', '좀', '알려', '주', '세요', '.']
print(mecab.nouns(u'우리나라에는 무릎 치료를 잘하는 정형외과가 없는가!'))
['우리', '나라', '무릎', '치료', '정형외과']
print(mecab.pos(u'자연주의 쇼핑몰은 어떤 곳인가?'))
[('자연', 'NNG'), ('주', 'NNG'), ('의', 'JKG'), ('쇼핑몰', 'NNG'), ('은', 'JX'), ('어떤', 'MM'), ('곳', 'NNG'), ('인가', 'VCP+EF'), ('?', 'SF')]지금까지 Mecab의 설치 후 적용을 진행해봤다.
이제부터는 본격적으로 Mecab의 User(Custom) Dictionary를 적용해보자.
4. Custom Dictionary 작성
원하는 Custom Dictionary를 작성하기 전에 다음과 같은 특성을 알아야한다.
시스템 사전 항목 추가 : 사전 업데이트가 잦지 않고, 속도 저하를 원하지 않는 경우
사용자 사전 항목 추가 : 사전 업데이트가 잦고, 관리자 권한이 없는 경우
CalyFactory 프로젝트는 작업 특성 상, 사용자 이벤트 분석 데이터가 자주 갱신될 것이므로 사용자 사전에 등록을 진행한다.
2번 과정에서 다운로드 받았던 mecab-ko-dic의 하위 디렉토리 user-dic에서 다음과 같은 목록을 확인할 수 있다.
userdic/
├── nnp.csv
├── person.csv
├── place.csv
└── README.md
각각의 파일마다 다음과 같이 추가할 수 있다.
- 일반적인 고유명사 -> nnp.csv
- 인명 -> person.csv
- 지명 -> place.csv
기존 파일이 아니더라도 새로운 파일을 형식에 맞게 추가만 하면 동일하게 인식한다. 사용자 분석 데이터 중 장소를 알기 위해 파일을 추가했다.
├── nnp.csv
├── person.csv
├── place.csv
├── restaurant.csv
├── sub-region.csv
├── subway.csv
├── university.csv
└── README.md
여기서 .csv 파일은 다음과 같은 형식을 가진다. (출처)
| 표층형 (표현형태) | 0 | 0 | 0 | 품사 태그 | 의미 부류 | 종성 유무 | 읽기 | 타입 | 첫번째 품사 | 마지막 품사 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 서울 | 0 | 0 | 0 | NNG | 지명 | T | 서울 | * | * | * | * | |
| 불태워졌 | 0 | 0 | 0 | VV+EM+VX+EP | * | T | 불태워졌 | inflected | VV | EP | * | 불태우/VV/+어/EC/+지/VX/+었/EP/ |
| 해수욕장 | 0 | 0 | 0 | NNG | T | 해수욕장 | Compound | * | * | 해수/NNG/+욕/NNG/+장/NNG/* |
포맷에 맞게 .csv 파일을 입력하고 나서 다음 커맨드를 통해 사전 컴파일로 user-dic을 적용하면 custom dictionary가 적용된 것을 볼 수 있다.
./mecab-ko-dic/tools/add-userdic.sh
make install

Comments