머신러닝에 대해 알아보자. (본 포스팅 모든 자료의 출처)
먼저 머신러닝은 기존 데이터셋을 가지고 시작하느냐?아니냐?라는 분류를 통해
Supervised Machine Learning과 Unsupervised Machine Learning으로 나뉜다.
우리가 알아볼 것은 기존 데이터셋을 통해 학습하는 Supervised Machine Learning이다.
Supervised ML
기존 데이터셋을 다음으로 가정해보자.
| X | Y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
여기서 X는 학습시간, Y는 성적으로 볼 때, 들인 학습시간에 비례해서 성적이 높아지는 것을 알 수 있다.
이 데이터를 가장 근접하게 그리는 그래프를 그린다면 다음 값도 예측할 수 있을 것이며,
1차 방정식의 형태를 가질 것이다라는 가설로 다음 식을 가질 수 있다.
H(x) = Wx + b
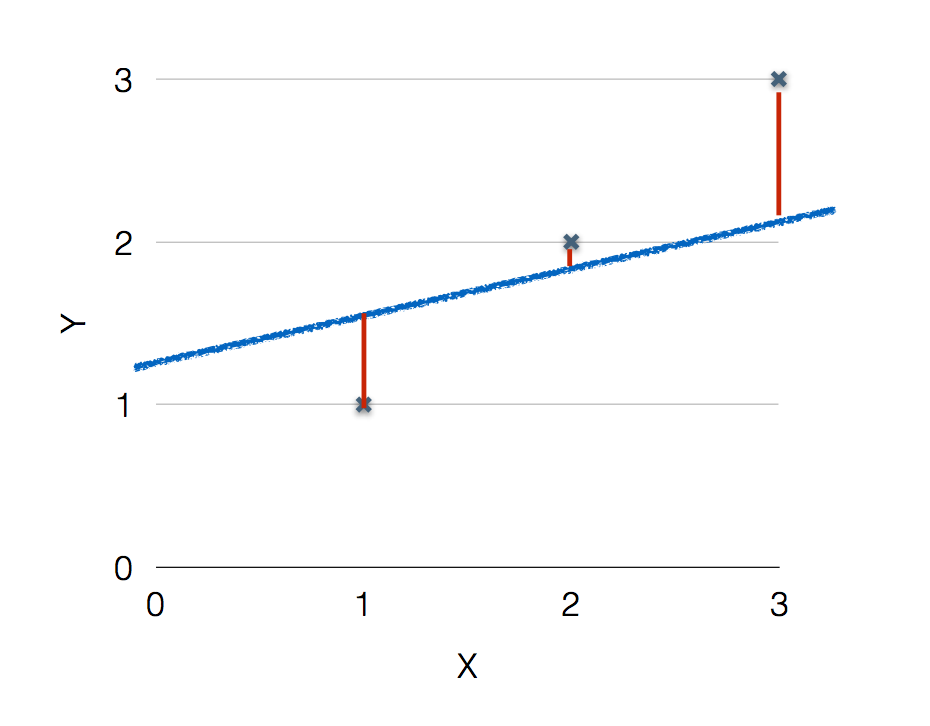
테이블에 대입한 값 H(x)와 실제값 y의 차이를 보면,
위 그림과 같이 얼마나 차이나는지를 알 수 있으며, 그 차이를 cost(혹은 loss) function이라 한다.
이 차이를 제곱하여 값을 비교하는데, 제곱으로 인한 장점은 다음과 같다.
- 항상 양수값이므로 비교가 쉽다
- cost function은 그 차이를 줄이기 위한 함수이기 때문에, 차이가 날수록 값이 크게 된다.
결과적으로 효과성 입증이 더 쉽다는 장점이 있다.
이 모든 값을 더하면 총 cost 값이 나오는데, 이를 최소화해야 실제 데이터와 가장 근접한 그래프가 나온다.
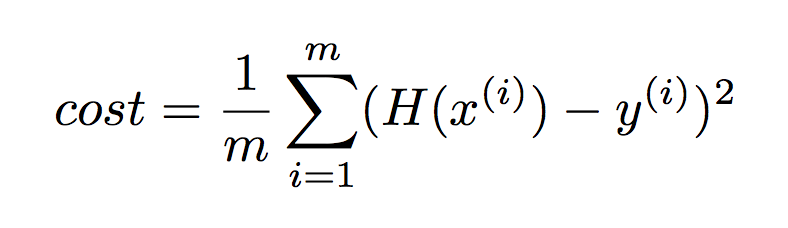
이를 찾기 위한 알고리즘이 gradient descent이다.
Minimize cost
cost의 최소화값을 찾기 위한 gradient descent는 다음 그래프의 형태를 가진다.
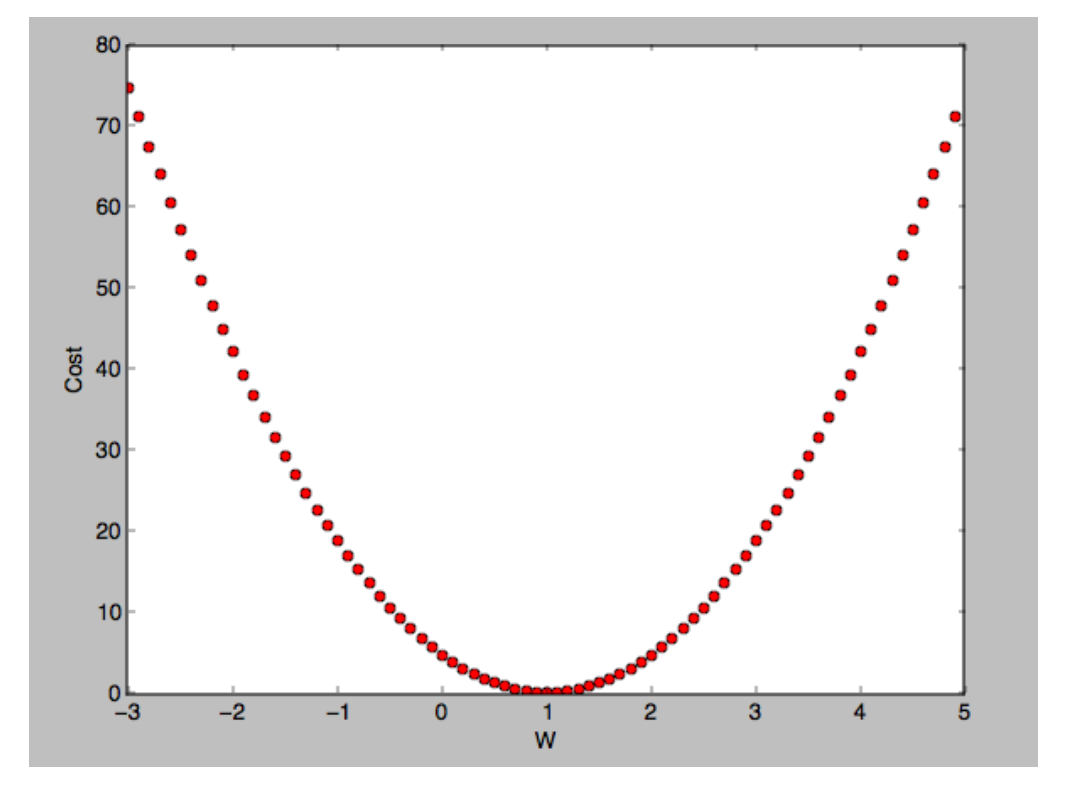
어떤 지점에서 시작하건, w값을 조금씩 변경해서 경사도를 비교 확인한다.
경사도를 확인하는 방법은 미분이며, 다음 과정을 거친다.
먼저 미분을 하기 쉽도록 2를 기존 cost 함수에 나눠준다.
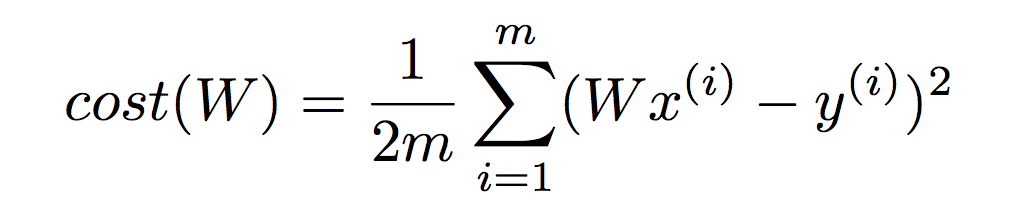
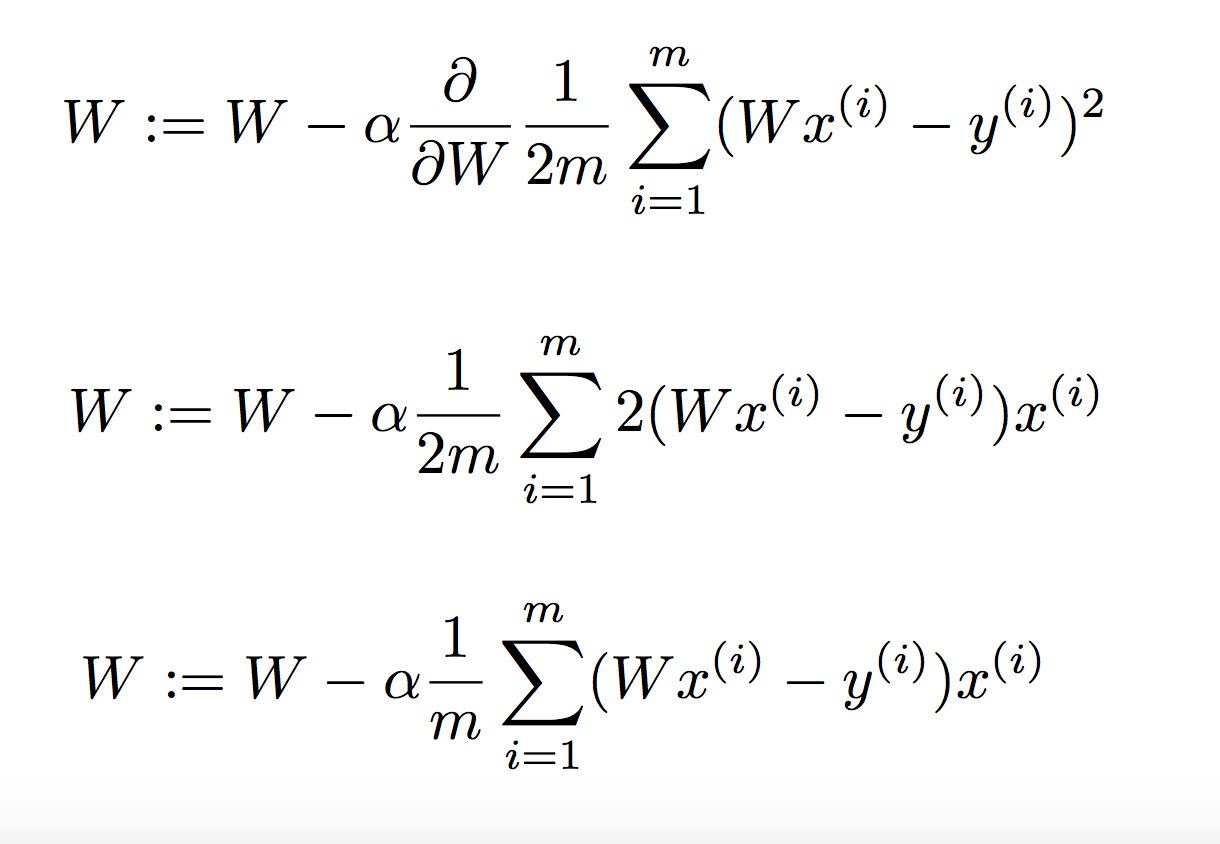
계속해서 다음 미분값을 통해 기울기가 0인 지점에 이르면, 최저점이므로 그 때의 cost는 최저값을 가진다.

Comments