Python을 활용해 간단한 Converter를 만들어보겠다.
이전 포스팅, MeCab에 사용자-라이브러리 연동하기에서 표준 스펙인 다음 표를 변형하여 분류를 하기로 결정했다.
| 표층형 (표현형태) | 0 | 0 | 0 | 품사 태그 | 의미 부류 | 종성 유무 | 읽기 | 타입 | 첫번째 품사 | 마지막 품사 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 서울 | 0 | 0 | 0 | NNG | 지명 | T | 서울 | * | * | * | * | |
| 불태워졌 | 0 | 0 | 0 | VV+EM+VX+EP | * | T | 불태워졌 | inflected | VV | EP | * | 불태우/VV/+어/EC/+지/VX/+었/EP/ |
| 해수욕장 | 0 | 0 | 0 | NNG | T | 해수욕장 | Compound | * | * | 해수/NNG/+욕/NNG/+장/NNG/* |
그를 위해 표준 스펙의 읽기 분류를 각 카테고리 항목으로 분류하는데, 현재 3,000여개 정도로 확보된 사용자 사전 워드들을 수작업으로 분류하기엔 시간이 너무 걸리는 상태.
Python을 사용해 값을 변경해주는 일종의 Parser를 구현했다.
먼저 입력할 커맨드의 형태는 다음과 같다. 이유는 뒤에서 코드와 함께 설명하겠다.
python3 converter.py restaurant.csv 식당
Parser가 읽어야할 input.csv는 다음과 같다.
신촌황소곱창,,,,NNP,지명,T,신촌황소곱창,*,*,*,*,*
호타루,,,,NNP,지명,F,호타루,*,*,*,*,*
스시마이우,,,,NNP,지명,F,스시마이우,*,*,*,*,*
읽고나서 출력될 output.csv는 다음과 같다.
신촌황소곱창,,,,NNP,지명,T,식당,*,*,*,*,*
호타루,,,,NNP,지명,F,식당,*,*,*,*,*
스시마이우,,,,NNP,지명,F,식당,*,*,*,*,*
먼저 파일 이름을 static하게 python파일 자체에서 가지고 있는 것보다,
외부에서 바로 입력해 처리할 수 있도록 command-line을 입력하는 것이 좋을 것이다.
이 입력을 위해 sys 라이브러리를 사용하고, 원하지 않는 커맨드 파라미터 수인 경우, 경고와 함께 종료한다. (python3 converter.py의 경우 sys.argv는 이미 1)
import sys
if len(sys.argv) < 3 :
print("arguments length is under 1. input string to argument for convert.")
sys.exit()
if len(sys.argv) > 3 :
print("arguments length is over 3. input two string to argument for convert.")
sys.exit()
# Check input file name
print('file name : '+str(sys.argv[1]))
현재 디렉토리를 입력하고 나면, 현재 디렉토리에서 위치한 파일의 정보가 있는지 먼저 검사한다. 존재하지 않는 파일의 경우, 종료.
from pathlib import Path
pathString ='./csv/'+str(sys.argv[1])
path = Path(pathString)
if path.exists() == False:
print(path+" is doesn't exist file")
sys.exit()
다음으로, 경로의 csv 파일을 읽는다. 변경할 부분만을 잘라서 마지막 커맨드라인 ‘식당’으로 변경한 뒤에 다시 이어붙인다.
with open(pathString, newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
split = ' '.join(row).split(',,,,NNP,지명')
convertedPart = split[1].replace(split[0],str(sys.argv[2]))
converted = split[0]+',,,,NNP,지명'+convertedPart
마지막으로 file.write()를 이용해서 새로운 csv파일을 생성한다. (csv.writer()을 이용할 경우, 기본값으로 ,가 들어가며 delimeter를 ‘ ‘로 변경하더라도 어색하게 띄워진 값들이 들어간다.)
with open(writePath, 'a', newline='') as file:
file.write(converted+'\n')
이 file.write()는 for row in spamreader: 라인 마지막에 들어간다.
반복 루프 마지막마다 파일의 행에 입력하기 위함이며, ‘a’ 포맷으로 open하는 이유는 ‘이어쓰기’위해서이다. (커서가 처음부터 시작하여 새로 작성하도록 하려면 w옵션을 주면 된다.)
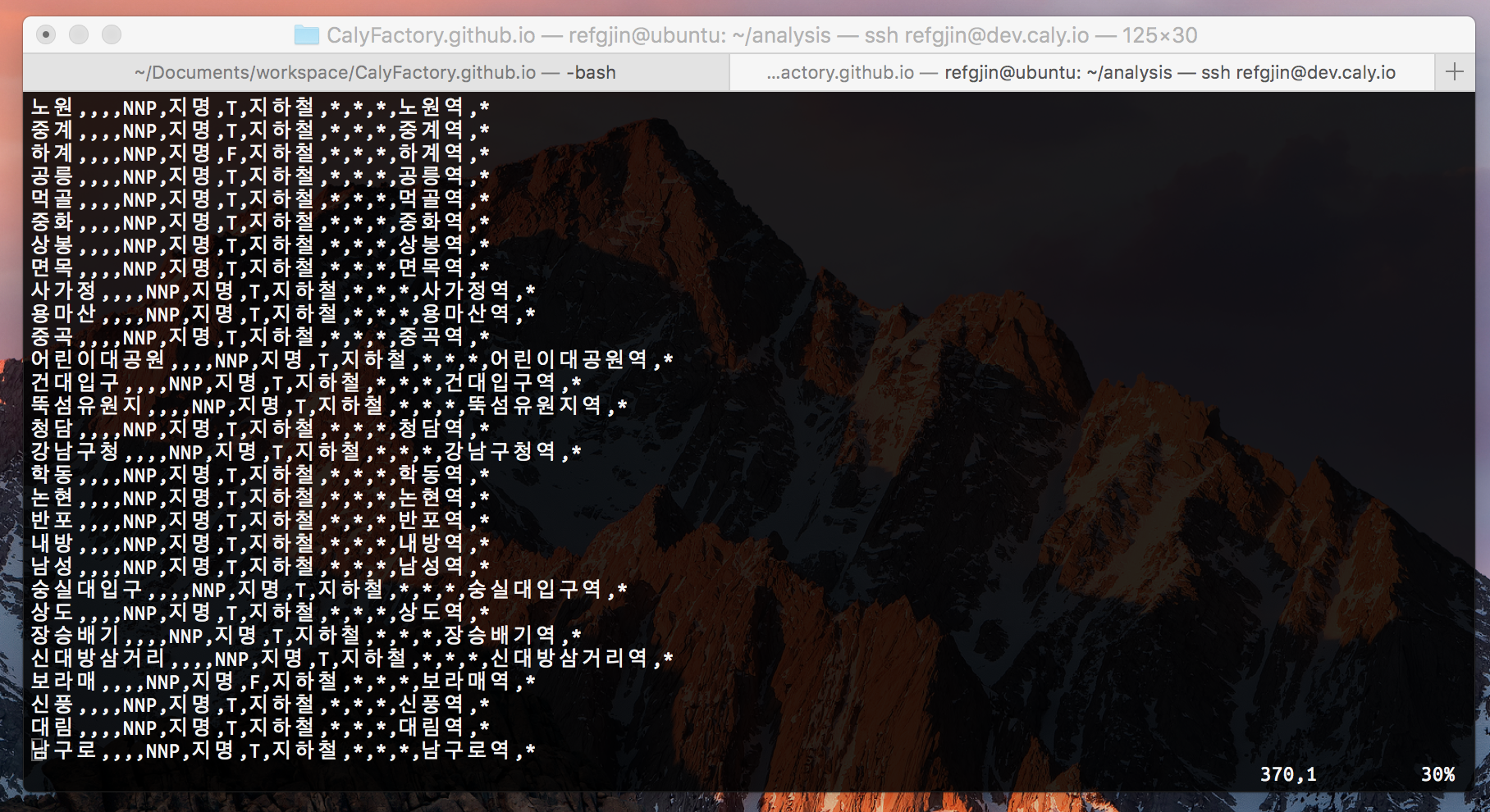
코드를 진행한 결과 예상했던 output.csv로 잘 출력되는 것을 확인할 수 있다.
하지만 다른 형식의 csv에서 원하지 않는 방향으로 진행되는 것을 확인했다.
# Expected result
가능,,,,NNP,지명,T,지하철,*,*,*,가능역,*
가산디지털단지,,,,NNP,지명,T,지하철,*,*,*,가산디지털단지역,*
# Result
가능,,,,NNP,지명,T,지하철,*,*,*,지하철역,*
가산디지털단지,,,,NNP,지명,T,지하철,*,*,*,지하철역,*
’,,,,NNP,지명,’을 기반으로 split해서 그 뒤에 ‘가능’을 모두 ‘지하철’로 변경하다보니
원하지 않았던 마지막 부분의 ‘가능역’ 또한 ‘지하철역’으로 바뀌는 것.
이를 변경하기 위해 converter.py의 변경로직을 바꾸었다.
with open(pathString, newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
split = ' '.join(row).split(',,,,NNP,지명')
>>>>>>
convertedPart = split[1].replace(split[0],str(sys.argv[2]))
======================
split2 = split[1].split(',*,*,*,')
convertedPart = split2[0].replace(split[0],str(sys.argv[2]))+',*,*,*,'+split2[1]
<<<<<<
converted = split[0]+',,,,NNP,지명'+convertedPart
그 결과 예상했던 대로 결과가 나오는 것을 확인할 수 있다.

Comments